

大阳城app注册下载(SuncityGroup) Claude Fable 5最难档零分! 智能体的终末查验来了
机器之心剪辑部 这几天,Anthropic 的最新模子 Claude Fable 5 发布之后,在 AI 圈激起了不小的振荡。 今天一早,大模子评测平台 Arena 放出了智能体基准测试(Agent Arena)的获利:Fable 5(High)排行第一,OpenAI 的 GPT-5.5(xHigh)屈居第二。另外,在「阐发胜仗率」和「可提醒性」等两方式的上,Fable 5(High)也稳压 GPT-5.5(xHigh)。 从 Agent Arena 的跑分来看,Fable 5 的性能强悍可见...


机器之心剪辑部
这几天,Anthropic 的最新模子 Claude Fable 5 发布之后,在 AI 圈激起了不小的振荡。
今天一早,大模子评测平台 Arena 放出了智能体基准测试(Agent Arena)的获利:Fable 5(High)排行第一,OpenAI 的 GPT-5.5(xHigh)屈居第二。另外,在「阐发胜仗率」和「可提醒性」等两方式的上,Fable 5(High)也稳压 GPT-5.5(xHigh)。
从 Agent Arena 的跑分来看,Fable 5 的性能强悍可见一斑。该基准通过数百万个着实宇宙的长周期智能体任务来评估模子,需要调用网页搜索、文献系统、终局等器用,完成写代码、制作幻灯片、网页商议、构建行使以及分析文档等复杂责任流。
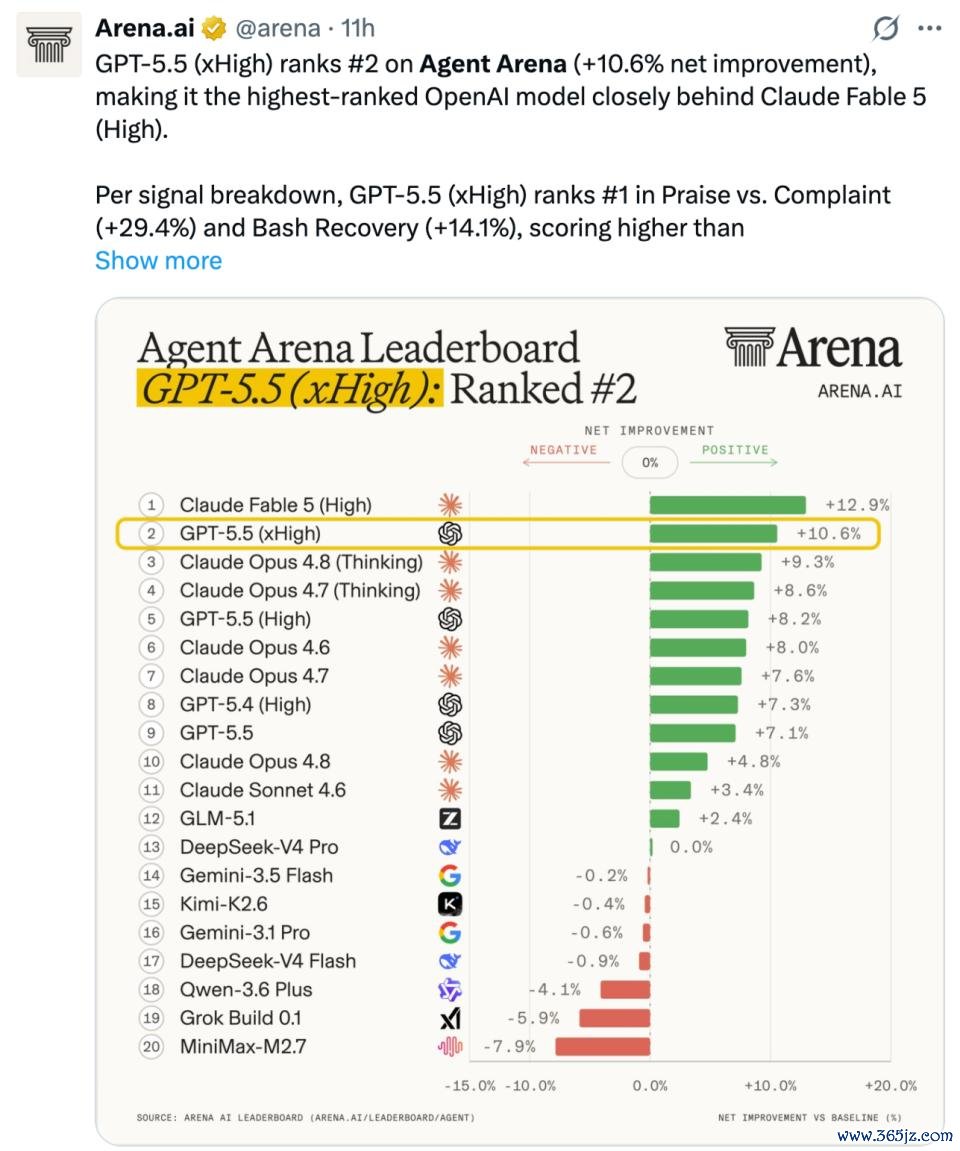
但与此同期,在另一个智能体基准测试中,Fable 5 败给了一个多月前发布的 GPT-5.5。
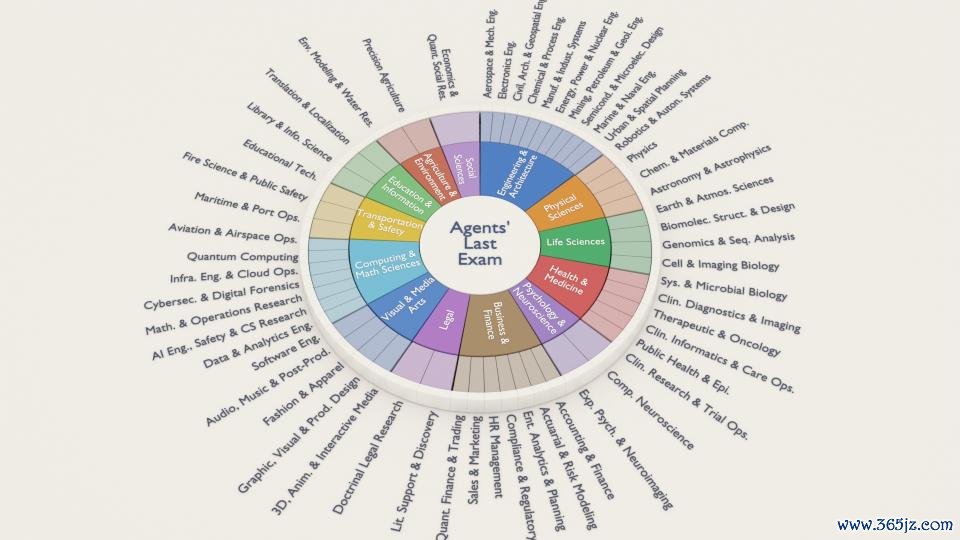
它是加州大学伯克利分校宋晓东(Dawn Song)教诲团队诞生的 ALE,全称为 Agents' Last Exam(智能体的终末大阳城app注册下载(SuncityGroup)查验),用来探究 AI 智能体是否确凿大要在泛泛的着实宇宙限度中完成具有经济价值的责任。
ALE 测试涵盖 55 个非膂力处事,包含 1500 + 项任务,由来自 100 + 机构的 300+ 位众人孝顺,隐蔽科学、工程、医学、法律、金融、教育等多个限度。另外,该基准提供完满的 GUI + CLI 环境,并基于最终效果进行可考据评估。
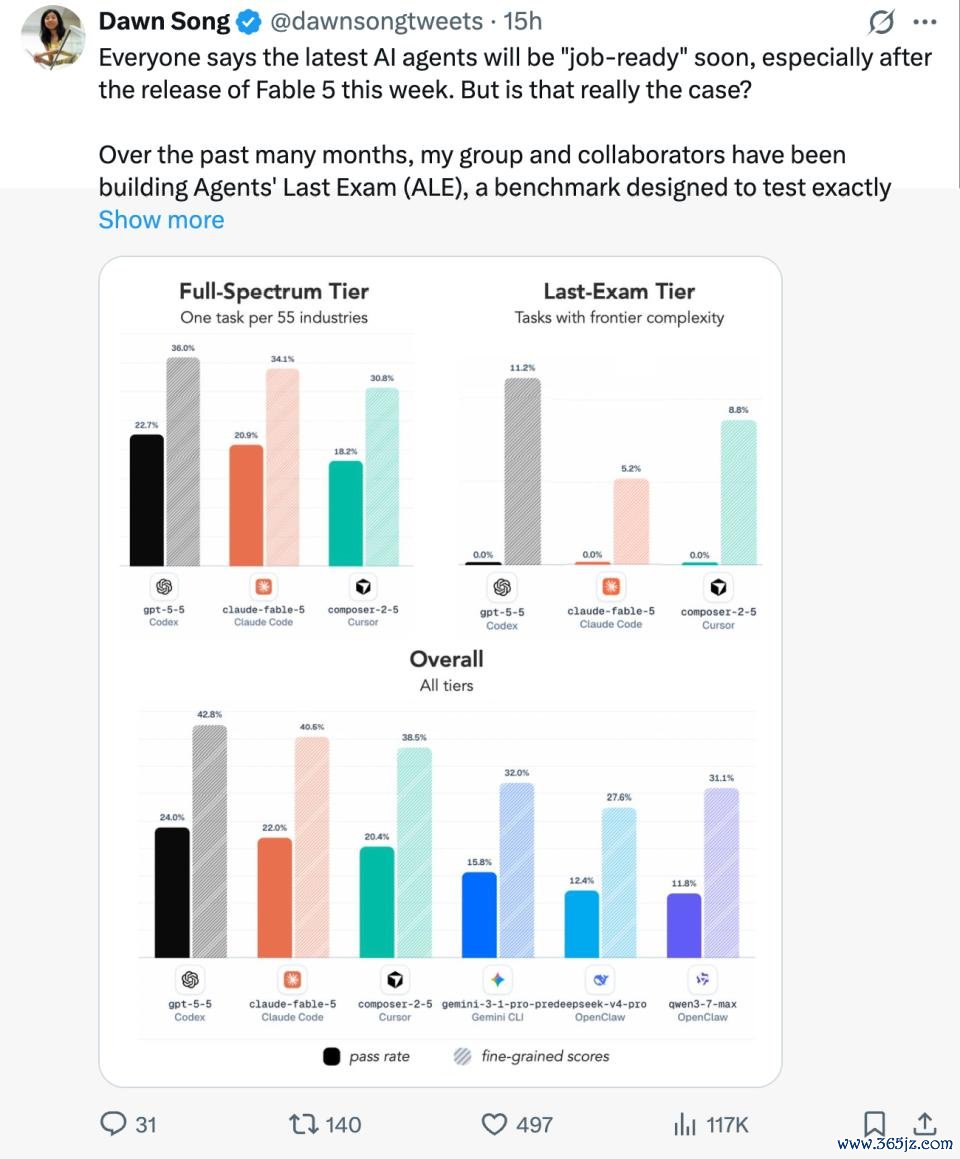
在 ALE 中,团队评测了 Fable 5、GPT-5.5、Composer 2.5 以非常他前沿 Agent 系统。效果既令东说念主印象深远,也富有让东说念主厚重:
当今的 Agent 依然大要管制非常一部分专科任务,但当咱们看向最难的那一类任务,也即是那些需要抓续推理、深厚限度学问,以及长周期可靠实施的任务时,它们距离东说念主类水平仍然很远。「灵验的 Agent 期间依然到来,但着实能胜任责任的 Agent 期间,还莫得。」
团队但愿 ALE 大要成为一个新的参照系,匡助行业诞生出大要在泛泛限度中沉稳完成经济价值责任的 Agent。
针对 Fable 5,ALE 的以下几点测试效果值得咱们怜惜:
一是,在举座榜单中,GPT-5.5 凭借 24.0% 的通过率居于榜首,稀奇了 Fable 5 的 22.0%;余下纪律为 composer-2.5、Gemini-3.1-pro-preview、Deepseek-v4-pro 和 Qwen-3.7-Max。
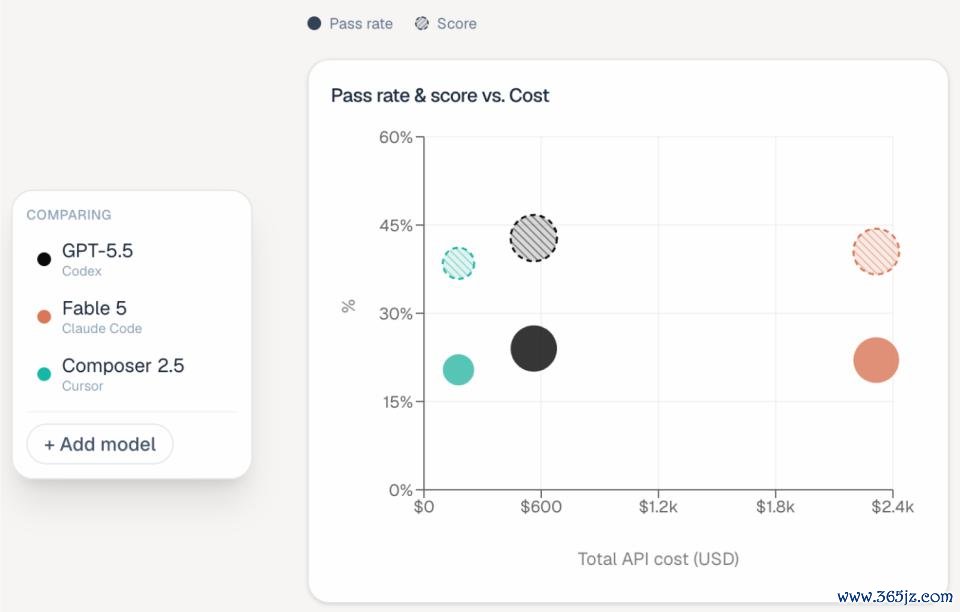
二是,老本互异雄伟。诚然 Fable 5、GPT-5.5 和 Composer 2.5 的举座发达处在合并梯队,但每项任务的老本互异相当彰着:Fable 5 平均每题破耗约 $15.70,GPT-5.5 仅 $3.80,Composer 2.5 为 $1.33。
也即是说,在性能左近的情况下,Fable 5 每完成一项任务的老本约莫是其他模子的 4 到 12 倍。
三是,最难一档拔本塞原。在最高难度「Last-Exam」档位,包括 Fable 5 在内的总计前沿 agent 通过率为 0%。
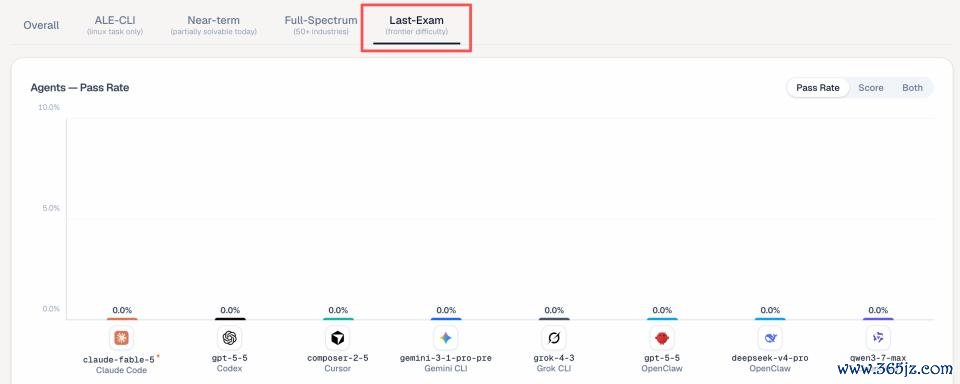
另外,ALE 中还有一个仅相沿敕令行环境的子集 ——ALE-CLI。
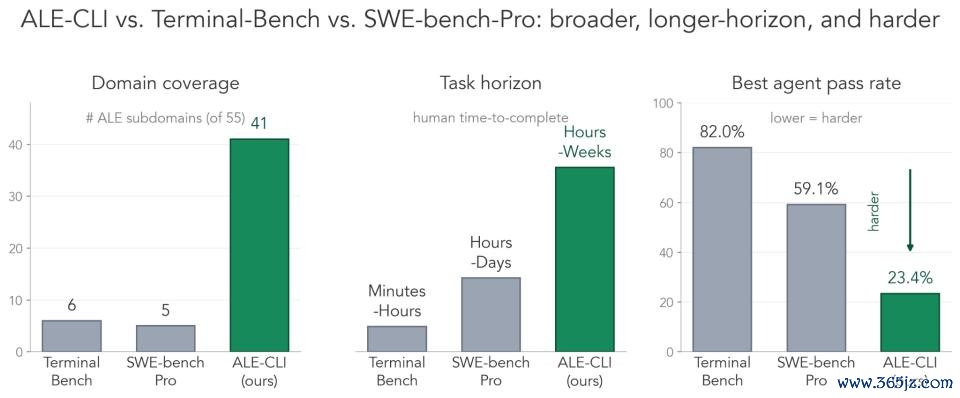
比较 Terminal-Bench 和 SWE-bench-Pro,它的隐蔽范围更广、任务周期更长,难度也彰着更高:
隐蔽更广:ALE-CLI 的任务隐蔽 ALE 55 个行业子限度中的 40 个;比较之下,Terminal-Bench 只隐蔽 6 个,SWE-bench-Pro 只隐蔽 5 个。
周期更长:东说念主类完成这些任务常常需要数小时到数周,而不是几分钟到几天。
难度更高:发达最好的 Agent 通过率也唯有 25.2%;比较之下,Terminal-Bench 上的最好通过率为 82.0%,SWE-bench-Pro 为 59.1%。
这施展,Agent 离着实锻真金不怕火还有很长的路要走,也还有很大的栽植空间。
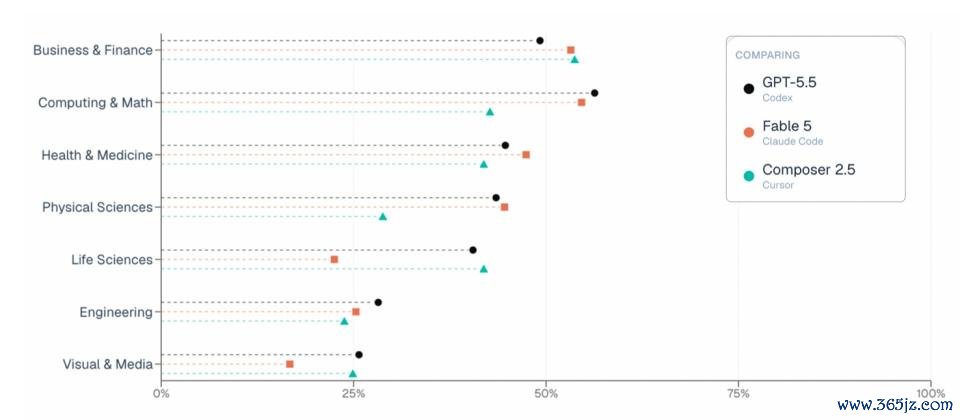
在谈到为什么 ALE 的效果和一些其他基准不太一样,尤其是 Fable 5?宋晓东暗意,原因很陋劣:不存在一个在总计场景下都最强的 Agent。包括 Fable 5 在内,每个前沿模子都有我方擅长的限度,也都有发达忙碌的限度。
总分会把 55 个处事、1500 多个任务的效果平均到一都,因此好多模子的分数会挤在左近区间。但着实弥留的,不是对等分。着实有价值的信号在于:Agent 在那里胜仗,在那里失败,以及这些成败模式怎样随限度而变化。一样的任务,大阳城app注册下载(SuncityGroup)不同模子失败的原因时时实足不同。
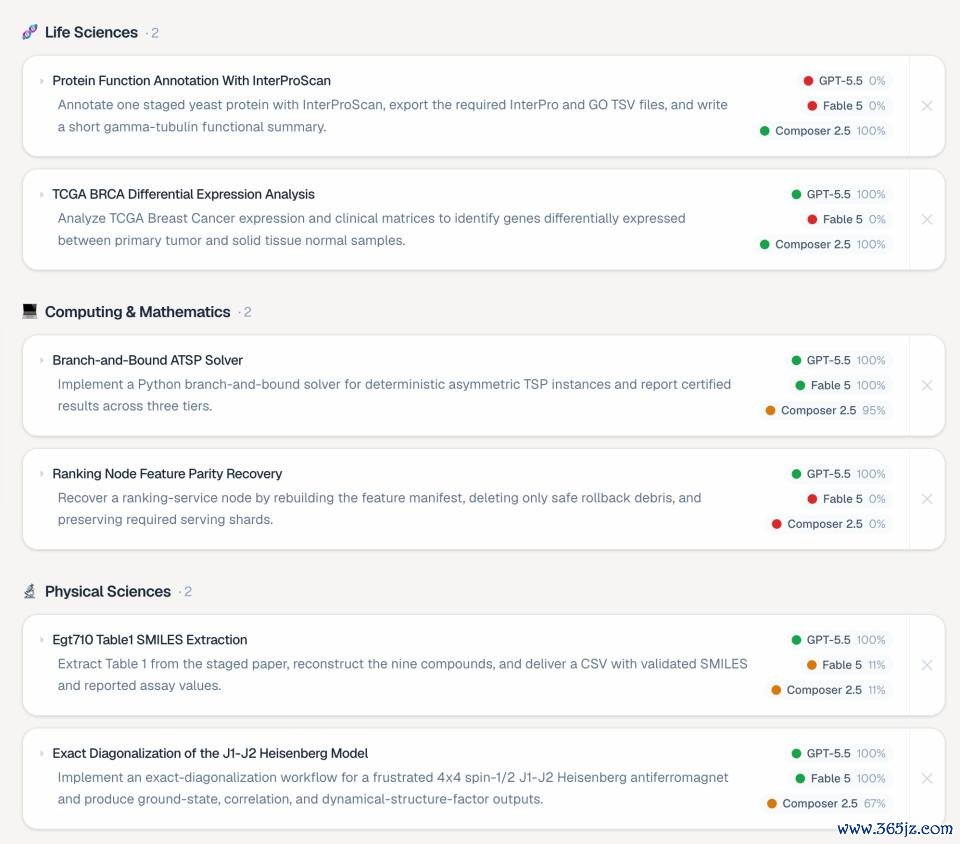
最常见的失败模式依然是一个练习的问题: Agent 还莫得着实考据我方的责任,就先书记任务完成。典型的完成回适时时是:「已完成,总计张望都通过了。」但履行输出可能短少必要文献、统计数目有误、遗漏要津字段,或者违犯了任务施展中明确写出的抵制条目。
ALE 商议先容

ALE 是一个包含 1000 多个任求实例的基准测试,隐蔽 55 个子限度和 13 个行业集群,由来自 100 + 机构的 300 + 位众人孝顺。
为了确保行业隐蔽富有泛泛且具有代表性,众人照看人委员会会梳理各个限度的责任流图景,并基于 O*NET / SOC 2018 处事分类体系,识别具有经济兴味的责任流类型。
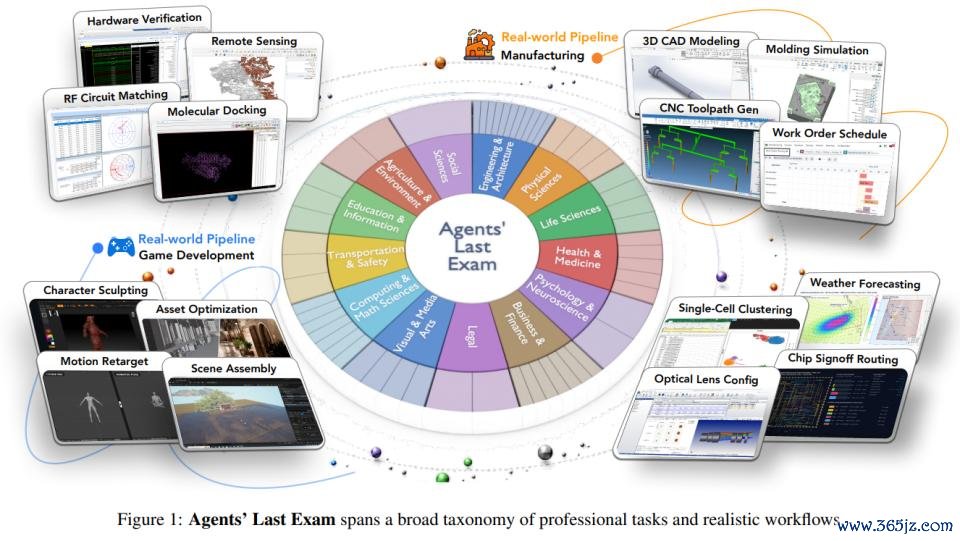
ALE 任务责任流来自着实的专科实践。它并不是诬捏商量合成场景,而是由众人提供他们依然完成过的着实方式。这些方式在被纳入基准之前,还要经过多轮质料甩掉,包括初步审核、工程师试驱动,以及众人委员会的最终同业评审。
大精深任务都要求智能体使用商量机,并在 GUI 交互和 CLI 操作之间来去切换。GUI 交互包括桌面行使、浏览器和特定限度软件;CLI 操作包括 shell 剧本、代码实施和文献处理。
这意味着,ALE 要求智能体同期具备多种智力,而这些智力在现存基准中时时是被分开测试的。
ALE 的标的评测对象是 GCUA(Generalist Computer-Use Agent)智能体,举例 Claude Code 或 Codex。这类智能体大要在合并个步履轮回中聚拢视觉感知、代码实施、器用使用和长周期规划。按照商量,ALE 的任务形态隐蔽范围要大于仅测试 GUI 的基准,举例 OSWorld,也大于仅测试 CLI 的基准,举例 Terminal-Bench 。
在职务集结上,ALE 不是敷衍集结一些任务来考验 AI,而是要求任务必须得志三个条目:
代表性。责任流应当稳妥着实的专科实践,并使用限度众人履行会使用的软件。举例,建筑限度众人在把 2D 蓝图调养为 3D 模子时,常常会使用 SolidWorks 或 Rhino,而不是 AutoCAD。
复杂性。一项任务应当是端到端的托付物,需要众人插足非常时刻完成,而不仅仅几个陋劣的 UI 操作。要津辞别在于:这是一个责任流,如故一个单一手脚。
可考据性。输出效果应当大要剿袭确定性张望,或者大要按照与可不雅察居品绑定的明确评分确定进行评估。最理思的情况是,托付物具有确定性,不错径直与参考输出进行比较。即使无法作念到精准匹配,判断也应当大要收复为对某个可测量居品的评估。
另外,ALE 中的任务不是由普通众包工东说念主来提供;而是来自限度专科东说念主士的着实日常责任,并经过严格筛选,以确保着实性、复杂性和工夫可实施性,共包含五说念关卡。
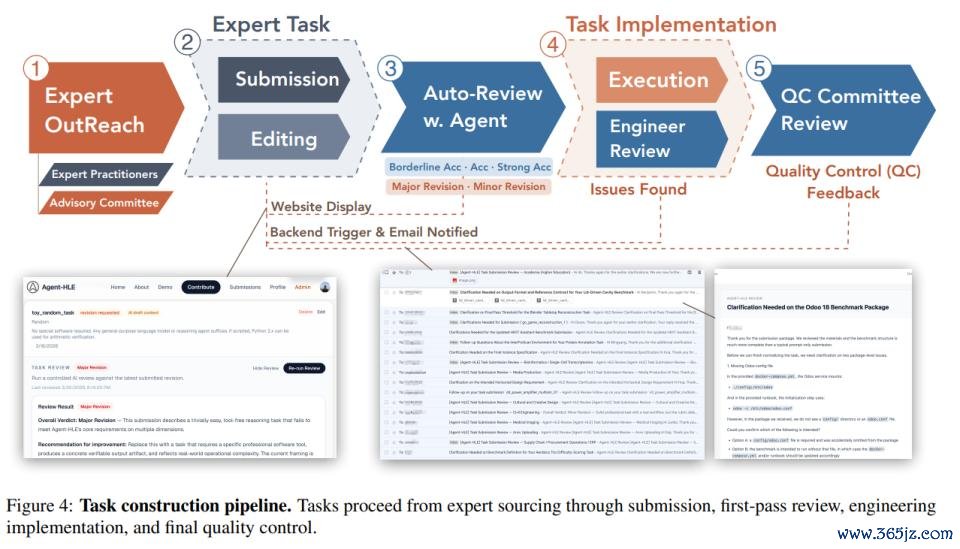
众人着手。商议者通过由行业从业者构成的照看人委员会招募限度众人,确保任务大要隐蔽通盘分类体系。
任务提交。众人通过有益的网页进口提交任务提案。他们会上传我方昔日完成过的方式,这些方式常常需要数天致使数周的专科责任。AI 援救器用会匡助完善每个提案,直到五个中枢构成部分被完满施展:当然讲话描绘、输入文献、标的软件、预期托付物和评测规律。
初步审核。提交内容会按照访佛学术会议审稿的容颜进行筛选,给出大修 / 小修、旯旮继承、继承、强继承等决定;需要修改的任务会复返给众人连续完善。
任求兑现。通过审核的任务规律会被变嫌为可驱动的资源、成就好的软件容器,以及编码后的评测逻辑。工程师会进行试驱动;一朝发现缺口,任务会被自动复返给众人补充。
最终质检。终末由众人委员会进行同业评审,核查参考输出是否正确,评测界限是否校准合理,既不成窄到简直不可能通过,也不成宽到诞妄宽松,同期阐发任务凹凸文是否充分。
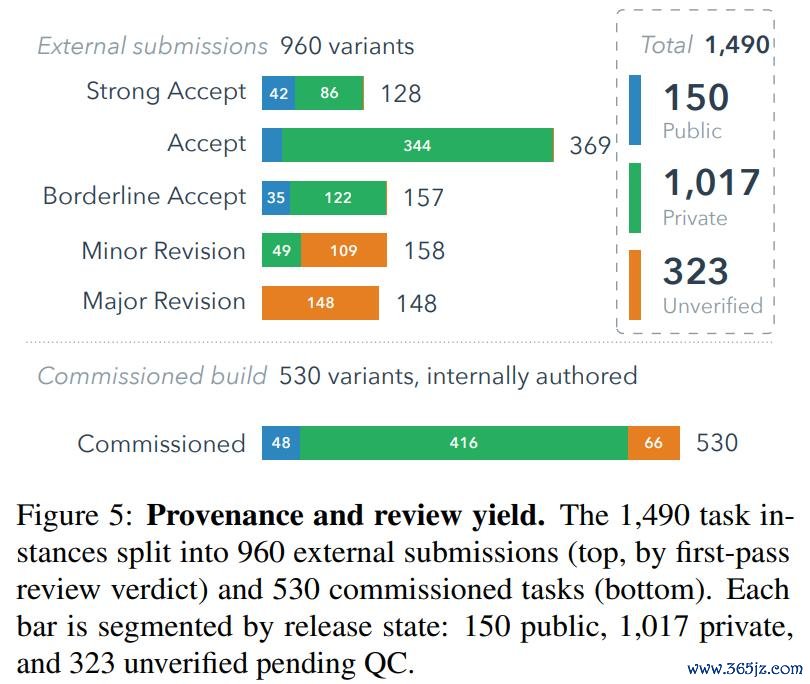
值得一提的是基准稠浊问题,这种稠浊可能来自预锤真金不怕火数据重迭,也可能来自针对具体任务的优化。为此,ALE 只公开 1490 个任求实例中的 150 个,约占 10%;其余任务保留在特有池中。
在具体评测历程上,ALE 将一个基准实例拆分为三个互相解耦的组件,这些组件通过界说了了的接口进行交互。
云开体育2026世界杯中国官网入口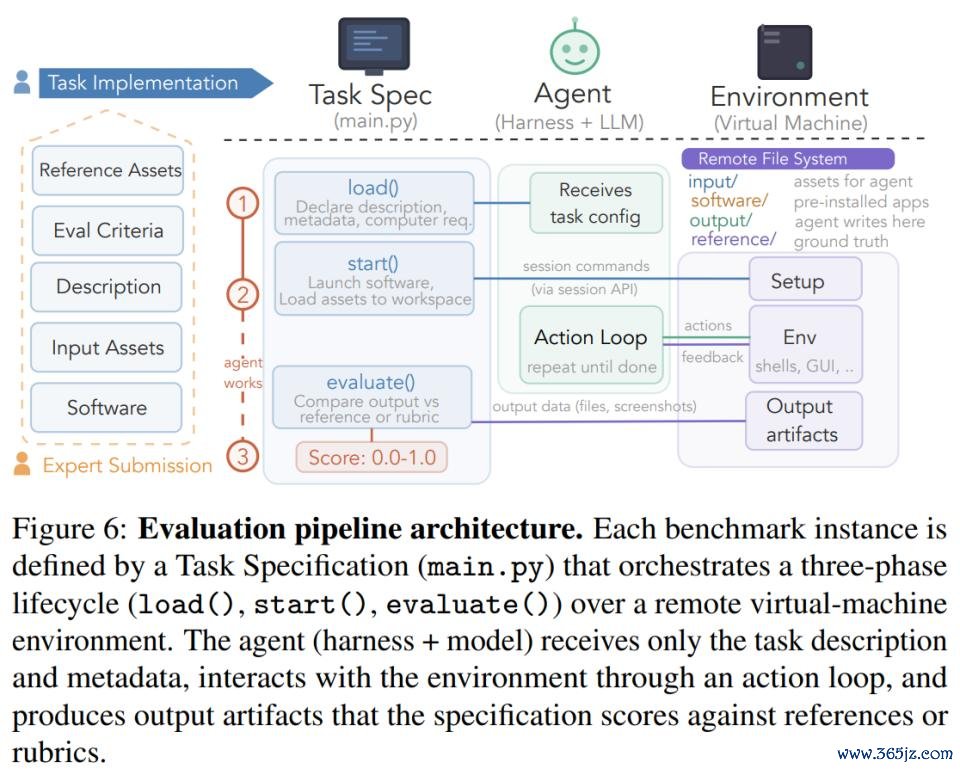
终末,团队但愿 Agents' Last Exam(ALE)大要成为一个新的路标和北极星,指引行业诞生出大要在泛泛限度中可靠完成经济价值责任的智能体。

